
Si parla molto di cosa stia cambiando nella SEO, quali siano le attività che funzionano ancora e quali siano ormai obsolete ed ovviamente ci sono molti pareri discordanti.
Si azzardano nuove teorie di content marketing e di link building a tutto spiano ma spesso si basano su una conoscenza distorta o poco approfondita di cosa sia realmente diventato Google.
Google, Bing e Yahoo il 2 giugno del 2011 si sono alleati in una causa comune, rendere il web più ricco di informazioni facilmente identificabili supportando schema.org nell’organizzazione di microdati in grado di individuare praticamente ogni cosa univocamente (approfondimento qui : http://searchengineland.com/schema-org-google-bing-yahoo-unite-79554)
Tre colossi si uniscono in una causa comune, dare a chi produce contenuti sul web la possibilità di essere molto più chiaro su cosa ci sia nelle sue pagine web per evitare che i motori di ricerca possano capirlo male e magari non premiarlo nei risultati di ricerca.
Dietro le quinte invece il motivo è da vedere da un altro punto di vista ma per capirlo bisogna prima avere un’idea di cosa accade quando Google individua un documento sul web.
Per questa breve spiegazione prenderò in prestito qualche slide dal nostro corso SEO basic.

Chi effettua una ricerca generalmente vuole informazioni su qualcosa di reale, un oggetto, una città, una persona, ma Google come fa a capirlo se i siti web sono semplici pagine di testo? Per anni ci ha provato utilizzando algoritmi basati sulla ricerca nel testo ma, per quanto fossero complessi, sono stati sempre ingannati in un modo o in un altro e Google è stato costretto ad introdurre algoritmi anti spam come Panda e mettere in piedi uno staff, il webspam team, per evitare che Google venisse ingannato in qualche modo.
Oggi Google non lavora più ricercando keyword nel testo ma entità ben precise, vuole un web fatto di dati e non di testi, c’è un gran parlare sul web sull’argomento semantica ma se Google non identifica perfettamente le entità non potrà mai capire il significato (Google non capisce, sia chiaro, prova ad indovinare la risposta studiando le relazioni tra le varie entità dei documenti/sito) e darvi la risposta esatta.
Alcuni motivi per cui Google vuole un web di dati:
- Ricercare in miliardi di pagine di testo è dispendioso in termini di tempo e si ha una qualità di ricerca bassa.
- Estraendo le entity dai documenti si genera un modello di dati più leggero e fruibile
- Avendo delle entity precise si possono gestire meglio le correlazioni ed individuare ambiti precisi (chi vende cosa, chi produce cosa, chi dipinge cosa)
- L’utilizzo delle entity nei siti web e le relazioni fanno capire a Google cosa faccia un determinato sito web
- Un sito web può essere menzionato, linkato, recensito per le entity che tratta. Google può “pesare” chi sia più di valore per determinate entity
Chi non ha alcuna esperienza di programmazione non può avere un’idea di quanto possa essere complicato per un programma capire di cosa si stia parlando, ma vediamo banalmente cosa accade in casa Google.
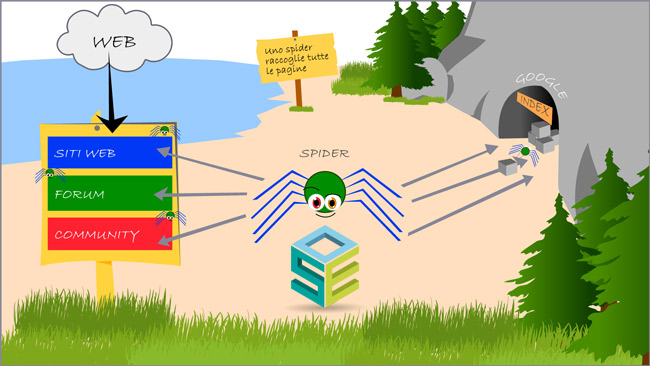
Lo spider naviga il web, siti, forum e qualsiasi altra tipologia di pagina accessibile, raccoglie le pagine e le porta in un archivio per farle valutare e vedere se meritino di finire nell’indice di Google.

Sul mucchio di pagine viene fatta una prima scrematura, vengono eliminati i documenti copiati, quelli di scarsa qualità ed i restanti vengono organizzati per argomento principale.

I documenti vengono passati al setaccio e vengono individuate tutte le entity, le relazioni tra le entity ne determinano quindi un Topic ed una Categoria in cui si trovano i Topic correlati.
Il processo per individuare le entity si chiama entity extraction in termini tecnici ed è a quel livello che ha importanza il testo dell’articolo. L’insieme di parole e frasi presenti nella pagina vanno a costituire un insieme, che io chiamo keyword space, che individua univocamente un’entità.
Questo in un mondo ideale… Ma non è esattamente così semplice, ci sono insiemi di parole che identificano cose diverse, quello che spinge Google a capire se si tratti di una entity o di un’altra è “la ricetta”, ossia il peso, la prominenza, la presenza di una o più frasi rispetto ad altre (questo lo misuro con un software da me realizzato Relevance di cui potete vedere un video qui).
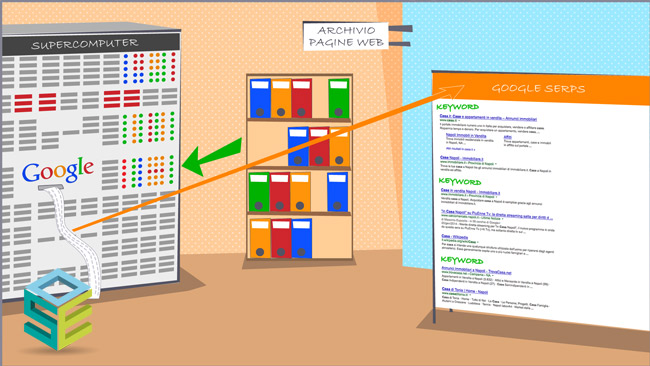
Quando viene fatta una ricerca Google prova a capire le intenzioni dell’utente e risponde “provando ad indovinare” i siti web più adatti proprio in base a come essi abbiano fatto uso delle entity e delle relazioni tra di esse. Capirete che provare ad ingannare un sistema del genere non sia così semplice. Qualcuno dice che basti inserire un nuovo concetto (entity) nello spazio delle entity del sito… Pensateci un po… Se nessuno ne parla sarà rilevante per Google? Certo che no! La cosa importante è toccare i tasti giusti, parlare delle entity giuste, nel modo giusto. Non servono entity nuove, serve solo capire dove siamo carenti e cosa abbiamo dimenticato. Se si tratta un argomento in maniera esaustiva la “semantica” va da se, puntate ad arricchire i contenuti e non date nulla per scontato.
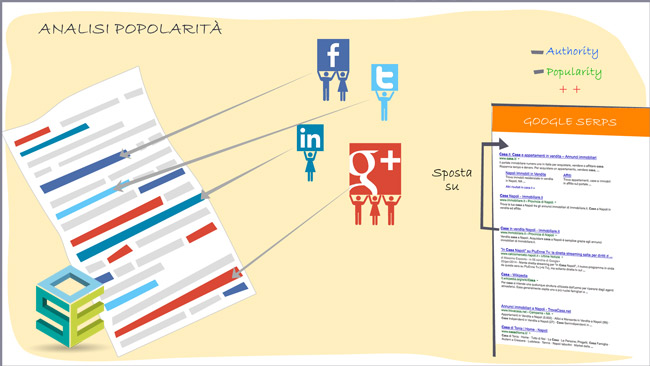
Una volta generata la pagina di risultati “grezza” viene fatto un ordinamento basandosi sui fattori di popolarità di ogni pagina web. In passato si parlava solo di link in entrata ma oggi è molto più complessa la situazione. Google oggi lavora su almeno quattro rappresentazioni schematiche delle ralazioni tra siti/entity e persone
- Knowledge Graph
- Social Graph (non quello di Facebook)
- Link Graph
- Engagement Graph
Non entro nel dettaglio perchè ci vorrebbe un altro post, magari lo scrivo in futuro, ma è giusto per rendere l’idea di quanti aspetti prenda in considerazione Google per capire se un sito/pagina sia popolare su un determinato argomento. Detto in parole povere, una pagina deve essere rilevante, chiara, famosa tra la gente, linkata, accattivante (deve creare engagement).
Quindi come si farà SEO nel futuro?
La SEO nel futuro, ma io già lavoro in questa direzione perchè è questa la direzione, deve essere orientata alla chiarezza, bisogna aiutare Google a capire esattamente cosa ci sia nelle pagine web utilizzando rich snippet (dove possibile) ed individuare il mix di keyphrases giuste per individuare una entity quando non è possibile farlo con i microdati.
Il problema più grande di Google è quello dell’ambiguità , con 10 ingredienti identici si possono fare decine e decine di ricette diverse, come fa Google a capirlo? In un modo o in un altro ci si avvicina ma se siamo chiari possiamo avere la meglio sui competitor.
Se non lo avete ancora visto, visitate la pagina del video del mio software Relevance che ho linkato in alto nel post, vi schiarirà un po le idee su alcuni aspetti.
Ma vediamo quali saranno le best practice SEO
- Prima di scrivere studiare bene l’argomento
- Individuate le entity rilevanti per il vostro business
- Individuate le relazioni tra le vostre entity che meglio definiscano il vostro business (la ricetta)
- Linkate in maniera naturale, i link in uscita arricchiscono un sito, non lo indeboliscono se usati bene
- I link in entrata sono sempre fondamentali
- I link in entrata devrebbero essere da siti a tema (stesso mix di entity e ontology)
- I link in entrata potrebbero anche provenire da “simpatizzanti” delle vostre entity (marginali)
- Condividete le vostre pagine sui social ma non con tutti, con chi potrebbe essere interessato
- La “vita” dei vostri post sui social ne determina anche la popolarità (shares, retwit, ecc…)
- Utilizzate l’authorship nei vostri post, anche voi siete un’entity “misurabile”
- Migliorate la user experience dei vostri siti… una volta arrivati Google vi “pesa” per vedere se meritate di essere al top.
Uno dei problemi principali è quello dell’individuazione delle entity e soprattutto delle relazioni utili al business.
A tal proposito sto realizzando un software che vi mostro in basso e che spero possa essere parte integrante del nostro SEO software (SEO Zoom).
Da una keyword di partenza, il software analizza tutte le ricerche più rilevanti e le raggruppa per macroargomenti, poi dal grafo ho la possibilità di individuare le entity che ritengo rilevanti incrociando i dati con l’altro mio software Relevance.
In questo modo posso sapere, di cosa parlare, in che modo, e cosa vuole la gente.
Nell’esempio ho utilizzato come base la parola chiave “ricerca agenti”.
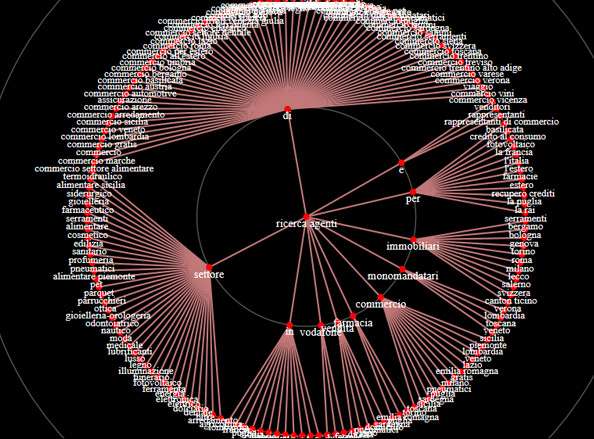
Il tool mi fa scoprire parole chiave di cui non ero neanche lontanamente a conoscenza (Serendipity Search, per restare nell’ambito della semantica)
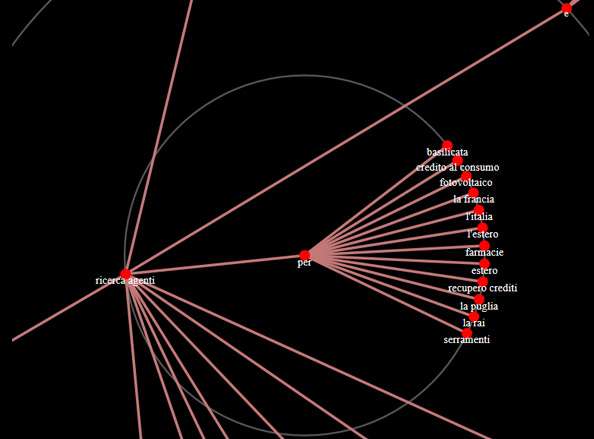
Ed ecco che scopro che gli utenti ricercano agenti per il recupero crediti o per le farmacie o per il credito a consumo, spunti utili per creare contenuti a tema sul sito ed anche per la discovery di link partners.
In questi ultimi mesi la SEO Cube è diventato un vero e proprio laboratorio di ricerca SEO, abbiamo limitato volutamente l’acquisizione di nuovi clienti e siamo tutti concentrati alla produzione di SEO Tool, se vi interessa rimanere aggiornati sullo sviluppo iscrivetevi su www.seozoom.com




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}