Il mese scorso ho avuto due speech sulla link building fatta in un web semantico al Bewizard di Rimini ed al WebUpdate 2015 a Napoli.
Il web Semantico come lo intendo io è un web fatto di dati e non di testo e manipolazioni concettuali, utilizzo di concetti correlati e tant altro.
Per mesi e mesi ho “battagliato” contro la disinformazione riguardo il web semantico finchè non ho deposto le armi perchè mi sono reso conto che per le masse è molto più “ispirational” credere che, con le proprie conoscenze limitate, si possano ottenere grandi risultati manipolando i testi delle pagine web piuttosto che sentirsi dire che c’è da studiare ed anche molto.
In un libro di Cialdini, “Le armi della persuasione”, è spiegato chiaramente che l’essere umano per evolversi ha la necessità di utilizzare concetti preconfezionati per ridurre al minimo la sua necessità di ragionare ed arrivare velocemente al passo successivo. Sfortunatamente quando i preconcetti sono sbagliati si persevera e si commettono sempre gli stessi errori senza mai soffermarsi sullo studiare la causa del problema, quel preconcetto che ti conduce all’errore senza che nemmeno te ne renda conto.
Uno dei preconcetti riguardanti il semantic web è quello che manipolando il testo di una pagina web sia possibile influenzare la base della conoscenza di Google arricchendo un argomento con altri “dettagli” che nessuno ha mai trattato.
Vi spiego per quale motivo questo è totalmente errato:
- Un sistema informatico basato sui dati che acquisisce (Google), riterrà vero/valido/attendibile un documento i cui contenuti trovano riscontro in tanti altri documenti dello stesso tipo
- Un argomento “latente” inserito in un documento, quando il motore di ricerca va a confrontarlo con “i parametri di settore”, lo vedrà come irrilevante e da filtrare e non porta alcun valore
Immaginate per un attimo di voler creare il nuovo Google, immaginate di voler partire da una singola parola chiave, analizzate tutti i testi di migliaia e migliaia di siti web che parlano dell’argomento e su 10.000 pagine analizzate individuate un subset di argomenti comuni in tutte e 10.000 pagine ma in 1 c’è un argomento non trattato da tutte le altre, cosa fareste lo scartereste o pensereste che 1 su 10.000 è l’unico che abbia il vero valore? Ovviamente io lo scarterei senza pensarci nemmeno, ed a dirla tutta, in un’ottica di individuazione di “argomenti comuni”, quello “extra” non lo noterei nemmeno perchè irrilevante.
A riguardo vi incollo uno stralcio di articolo di Ray Kurzweil, Google’s Director of Engineering
Issue #1: Irrelevant Noise
The algorithm uses a method of identifying facts that examines three factors in order to determine it. It refers to them as “Knowledge Triples”, consisting of a subject, a predicate, and an object. A subject is a “real-world entity” such as people, places or things. A predicate describes an attribute of that entity. According to the research paper, an object is “an entity, a string, a numerical value, or a date.”
Those three attributes together form a fact, known in the research paper as Knowledge Triples and often referred to simply as Triples. An example of a triple is: Barack Obama was born in Honolulu. The problem with this method is that extracting triples from websites results in irrelevant triples, triples that diverge from the topic of the web page. The research study concludes:
“To avoid evaluating KBT on topic irrelevant triples, we need to identify the main topics of a website, and filter triples whose entity or predicate is not relevant to these topics.”
The paper does not describe how difficult it would be to weed out irrelevant triples. So, the difficulty and time frame for addressing this issue remains open to speculation.
Oltre a chiarire il fatto chè gli elementi di disturbo ed irrilevanti saranno rimossi, ci tiene anche a precisare che fatti inutili saranno rimossi del tutto anche se è complicato e ci stanno lavorando.
Issue #2: Trivial Facts
KBT does not adequately filter trivial facts to set them aside and not use them as a scoring signal. The research paper uses the example of a Bollywood site that on nearly every page states that a movie is filmed in the Hindi language. That’s identified as a trivial fact that should not be used for scoring trustworthiness. This lowers the accuracy of the KBT score because a web page can earn an unnaturally high trust score based on trivial facts.
As in the first issue of noise, the researchers describe possible solutions to the problems but are silent as to how difficult those solutions may be to create. The important fact is that this second issue must be solved before KBT can be applied to the Internet, pushing back the date of implementation even further.
Bene dopo questa premessa, fintroppo lunga 🙂 arriviamo al dunque e vi dico cosa penso del semantic web e di come fare anche link building in questo nuovo scenario fatto di dati.
Perchè il semantic web
Uno dei motivi principali è quello legato alla crescita del web, ogni giorno vengono prodotti milioni di pagine web che Google deve “leggere”, intrpretare, catalogare, pesare, indicizzare e posizionare quasi in tempo reale.
Immaginate Google come una enorme libreria piena zeppa di libri e pagine di cui ricordare ogni singola frase, parola, risposta, qualcosa come la foto sottostante.

Ed il bello è che questi libri che Google ha messo in libreria, cambiano il loro contenuto continuamente e quindi è costretto a rileggerli ogni santo giorno, una vera follia non credete?
Oltretutto, ogni libro, potrebbe essere presente in tutte le lingue del mondo, dice le stessissime cose senza alcun valore aggiunto, solo che lo dice in lingua diversa, vale la pena di salvarlo in archivio nuovamente ed occupare tutto quello spazio?
La soluzione semantica
- Va bene leggere i libri tutti i giorni ma più rapidamente
- Estraggo solo le informazioni che mi interessano da ogni pagina (Entity, Fatti, Relazioni) in parole povere “il significato”da un punto di vista informatico e di dati
- Salvo le informazioni in un formato che occupi meno spazio
- Organizzo le informazioni in modo da poterle interrogare in tempo reale
- Oragnizzo le informaizoni in modo da tenere traccia delle relazioni con altre informazioni
Con questo metodo, un librone di 1000 pagine che prima occupava (ipoteticamente) un megabyte e tante risorse macchina per interrogarlo, oggi occupa 64kb di dati interrogabili con il minimo sforzo in termini di CPU e con tempi di risposta immediati. Oltretutto è molto più facile confrontarlo con altri dati dello stesso tipo in quanto perfettamente identificabili tramite Entity comuni e knowledge triples comuni.
Come google identifica le entità nelle pagine web
Google identifica le entità che conosce, il contesto in cui le stiamo usando, e le azioni che le riguardano e lo fa attraverso l’estrazione ed identificazione delle entity nel testo delle pagine web grazie all’utilizzo di software che Google chiama “Extractors” perchè in grado di estrarre i dati semantici che servono a costruire il web semantico dalle pagine web.
Un Extractor quando analizza una pagina web si può trovare dinanzi a due scenari diversi:
- La vecchia pagina web “non semantic web ready”, quindi testo ed immagini
- Una pagina web con tag di schema.org, html5 ed implementazioni di rich snippets
Quando un extractor incontra una pagina web vecchio stile non sarà in grado di fornire una precisione del 100% ed utilizzerà una estrazione implicita
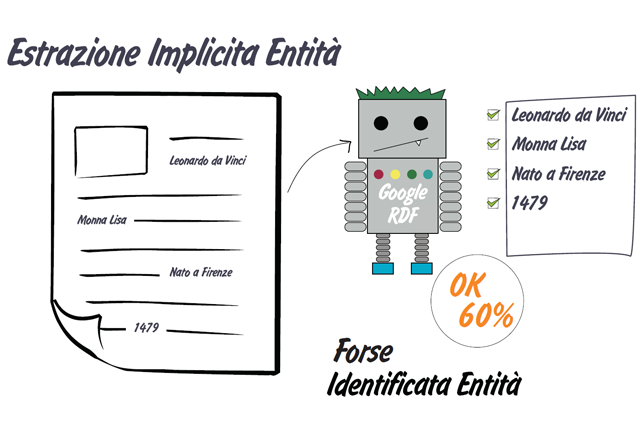
Quando invece un extractor incontra pagine con dati semantici ben organizzati ed esposti applicherà una estrazione esplicita molto più precisa.
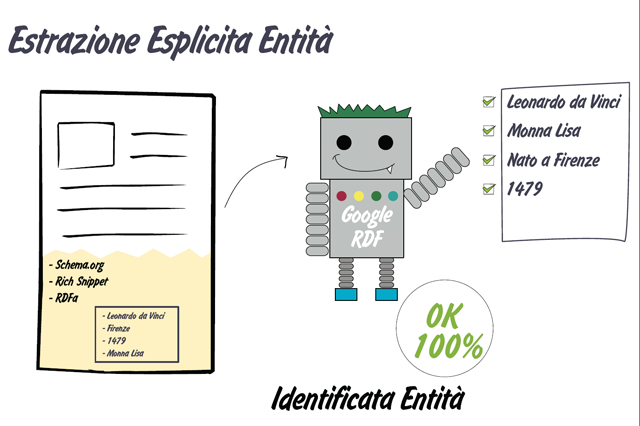
Una volta estratte le entità, Google prova a capire per quale motivo le stiamo utilizzando nella nostra pagina web per capire cosa vogliamo esprimere. Quali azioni sono associate all’entità di cui parliamo? Quali relazioni abbiamo evidenziato?
Analizzando le pagine web Google prova a costruire quindi le ontology, triple Soggetto->Predicato->Oggetto che gli permettano di sapere chi ha fatto cosa a chi o con chi.
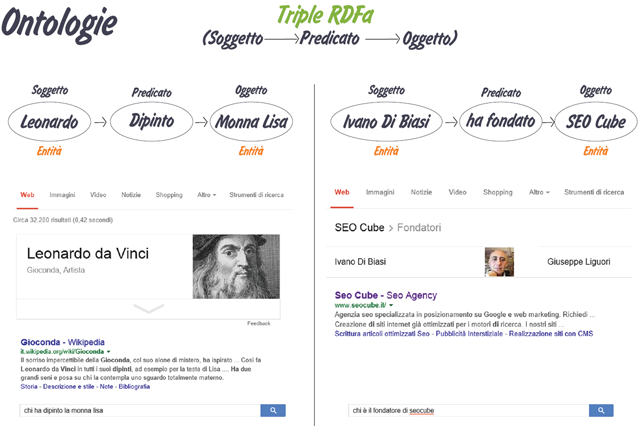
L’apetto più importante della semantica a mio avviso
Grazie alla semantica, Google può definire entità univocamente a livello globale, quindi una entità NON HA LINGUA è la stessa in tutto il pianeta e viene salvata nei database una volta sola, il suo nome non rappresenterà una nuova entità ma solo una proprietà dell’entità esistente, ecco perchè ritengo estremamente irrilevante la manipolazione testuale delle pagine web.
Di seguito vi incollo alcune slide che ho fatto per un mio corso di qualche anno fa dove provo a far capire cosa sia un’entità per Google e per quale motivo sia così importante e conveniente per lui estrarle e catalogarle per creare il web semantico.


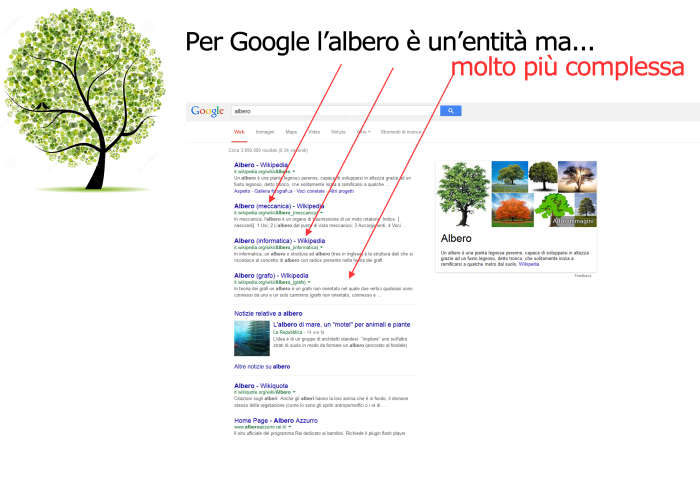

 Google essendo in grado di individuare entità e capire in che relazione siano con tante altre entità e fatti ha quindi anche la possibilità di identificare Brand, Aziende, Prodotti, Persone, Luoghi, Fatti e tant’altro.
Google essendo in grado di individuare entità e capire in che relazione siano con tante altre entità e fatti ha quindi anche la possibilità di identificare Brand, Aziende, Prodotti, Persone, Luoghi, Fatti e tant’altro.
Essendo in grado di identificare Aziende ed anche Persone ha anche il modo per capire quanto si debba fidare di tali entità quando le identifica come “publishers”!
La chiave per il successo di un sito web è esattamente quella della fiducia, ossia far fidare ciecamente Google di noi e dei nostri contenuti.
Campagne di Trust Building o link building semantica
Da un paio d’anni in SEO Cube facciamo link building in un modo molto singolare, parlando con tanti colleghi ho avuto conferma di essere l’unico a lavorare in questo modo, non sto dicendo che sia il modo ideale o il migliore ma sicuramente è un modo sicuro, pulito, non spammoso e con risultati che durano nel tempo, un metodo che ci ha fatto portare ai primi posti migliaia di parole chiave per clienti di settori super competitivi.
Al BeWizard di Rimini ed anche al WebUpdate ho parlato di questo nostro metodo di Trust Building basato sulla semantica ed ho provato a tirar fuori una metodologia concreta che vi permetta di analizzare, pianificare, agire e mettere in piedi una campagna di link building semantica
Potete scaricare le slide cliccando qui : Link Building Semantica
Volevo pubblicare anche il video del mio intervento al BeWizard ma lo stanno ancora preparando e potrò pubblicarlo solo dopo la loro pubblicazione ufficiale, se riesco vi pubblico qualche spezzone preso con l’Iphone dal mio socio 🙂





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}