Ancora una volta mi trovo costretto a parlare di SEO Semantica anche se è un argomento vecchio di sette anni. Mi trovo costretto a farlo perchè ancora oggi, quando ormai le conoscenze sulla semantica nei motori di ricerca dovrebbero essere mature, sento frasi del tipo “incastrare argomenti latenti” o “utilizzare concetti latenti” nei testi del sito per ottenere il posizionamento organico per determinate parole chiave.
Come funziona realmente Google non lo sa nessuno quindi non posso assolutamente dire che le mie affermazioni siano oro colato ma vi garantisco che sono frutto di uno studio sulla semantica nei motori di ricerca che ha inizio nel lontano 2007 quando, proprio grazie alle intuizioni sugli algoritmi semantici, sono riuscito a posizionarmi ai primi posti al campionato mondiale SEO creando una rete di entity e relazioni con tool da me realizzati.
Posizionamento su Google con la semantica
Alcuni affermano che sia possibile posizionare pagine web per parole chiave specifiche, individuando argomenti/significati “latenti” ed inserendoli nel testo della pagina web che si vuole posizionare o in pagine di approfondimento che saranno collegate con la principale da un link.
Questa affermazione è a mio avviso completamente sbagliata e frutto di una conoscenza molto marginale di come in realtà funzioni Google. C’è però da dire che questa affermazione, nonostante sia sbagliata, almeno fa capire in quale direzione muoversi, ossia il miglioramento dei contenuti del proprio sito web.
Non voglio assolutamente mettere la mia opinione contro quella di altri, vorrei piuttosto mostrarvi come funzionava Google 10 anni fa e come invece ha iniziato a funzionare dal 2007 in poi fino ad arrivare al cambiamento più concreto degli ultimi due anni dove la semantica è evidente anche nelle SERP con la presentazione dei Box della Knowledge Graph o col i “grassetti” su significati correlati alla keyword ricercata.
Quando la semantica non era ancora nei piani di Google ci trovavamo davanti ad uno scenario in cui i testi erano molto vicini alla comprensione umana (ovviamente) e tanto lontani dalla comprensione di Google, motivo per cui Google doveva utilizzare algoritmi evoluti, ma di vecchia concezione, che erano facilmente manipolabili da chi produceva i testi.
Quella era l’era in cui “andava di moda” il concetto di Keyword Density in quanto tutto l’impegno di copywriting era rivolto alla keyword singola ed al suo posizionamento. Google vedeva tutto “un po’ da lontano” ed era facile creare illusioni ed ingannarlo.

L’arrivo della semantica in Google e l’ RDF
L’errore, a mio avviso enorme, di chi parla di posizionamento semantico è che crede di aver solo bisogno di lavorare sul testo, e sui contenuti in genere, per poter posizionare un sito web dimenticando che Google ha introdotto la semantica proprio per evitare le manipolazioni delle SERP tramite la manipolazione dei contenuti, motivo per cui ha anche realizzato vari algoritmi antispam come Panda.
La realtà è che Google ha introdotto gli algoritmi semantici per i seguenti motivi:
- Per essere in grado di capire se un testo è a tema o se si tratta di semplice spam
- Per capire quali siano tutte le entità coinvolte in argomenti specifici
- Per capire quali siano le relazioni tra le varie entità di un argomento specifico
- Per capire quando relazioni diverse tra entità identiche riconducano ad un concetto/argomento diverso
- Per “pesare” la presenza delle entità all’interno di concetti che abbiano lo stesso “pool” di entità
- Per gestire più velocemente quantità di dati sempre più in crescita
- Per tradurre i significati, le intenzioni dell’utente, le relazioni tra le entità in una forma facilmente comprensibile da un software (Google)
Tutto il lavoro fatto da Google con la semantica ha un unico scopo, prendere un documento (vicino alla comprensione umana) e tradurlo in modo da comprenderlo meglio della maggior parte degli umani.
Vi potrà sembrare assurdo ma Google, leggendo un testo, sarà 1 milione di volte più veloce di qualsiasi essere umano nel comprendere il tema e la qualità (espressa almeno come quantità di informazioni, tematicità e correttezza) di qualsiasi essere umano.
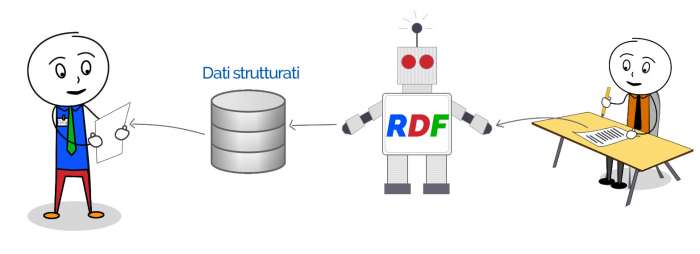
Per riuscire a fare tutte queste belle cose, Google ha introdotto un layer , il Resource Definition Framework (RDF) un algoritmo evoluto (in realtà sfrutta decine di altri algoritmi come quelli di Entity Extraction) che in parole povere, poverissime 🙂 fa quanto segue:
- Analizza il testo
- Identifica tutte le Entity (elementi importanti dell’argomento)
- Identifica tutte le relazioni tra le Entity
- Identifica nuovi significati/sinonimi per le entity sfruttando le anchor dei link che le referenziano internamente
- Traduce il tutto in formato leggero e comprensibile per Google
- Salva il tutto (qui andrebbero approfondite tante cose tecniche ma non è mia intenzione, approfondite qui se vi fa piacere)
Cosa fa Google con la Semantica
Ora viene la parte interessante, quella parte che dovrebbe completamente sfatare le teorie di chi dice di poter influenzare Google con l’introduzione di significati latenti ed altre teorie del genere, ora vi spiego perchè.
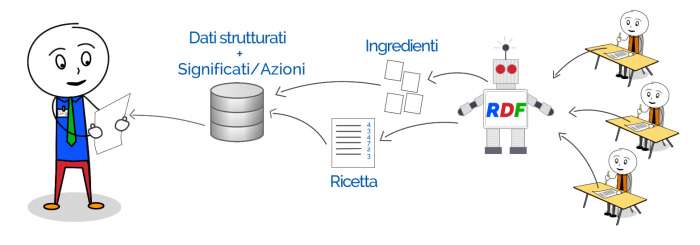
Google per farsi un’idea di cosa rappresenti un argomento specifico ha l’ovvia necessità di analizzare milioni di pagine web, milioni di testi e provare a capire quali siano tutte le entità che rappresentano l’argomento, diciamo quello che nei miei Tool definisco WordSpace.
L’insieme di tutte queste entità semantiche può essere visto come l’insieme di ingredienti che messi insieme, in modo corretto, ci permetteranno di ottenere il risultato finale. Google quindi, non solo analizzerà tutte le entità ma capirà (empiricamente) quale sia la ricetta perfetta per un testo che dovrebbe posizionarsi con una specifica parola chiave.
Il risultato finale di un’analisi semantica dei contenuti dei siti web a tema porterà per forza di cose ad una condizione del genere:
- Google avrà individuato tutte le entità che rappresentano un argomento (ma non saranno per forza usate tutte da tutti i siti)
- Google avrà individuato tutte le ontology che legano le entity (significato e semantica di termini e relazioni tra loro, ma anche in questo caso non tutti i siti le utilizzeranno)
Questi significati vengono salvati in forma di Triple dell’RDF (Entity->Azione->Entity) - Google, analizzando tutti i documenti, avrà capito qual’è il giusto equilibrio ed avrà trovato la “ricetta perfetta”
In uno scenario in cui Google lavora sui grandi numeri, acquisiti elaborando milioni di documenti, ed in cui ha trovato le sue risposte individuando tutte le entità, tutte le relazioni tra loro, ed il giusto mix di entity e relazioni per ogni singola parola chiave, per quale assurdo motivo “andare fuori tema” introducendo qualcosa di “latente” (che a lui sostanzialmente non interessa in quanto non individuabile come pertinente dal punto di vista algoritmico) potrebbe essere la chiave per posizionarsi su quella parola chiave?
A scuola, quando si facevano i compiti in classe, se trattavi qualcosa di latente stavi andando fuori tema, idem per Google, se parli d’altro ti allontani dal tema centrale.
Argomenti latenti per posizionare pagine web
Alcuni credono di aver ottenuto risultati trattando argomenti e/o concetti latenti perchè analizzando le pagine web dei siti meglio posizionati non hanno trovato riferimenti specifici all’argomento che hanno “incastrato” ma l’hanno trovato invece in altri siti web facendo ricerche simili.
La mia opinione è che queste persone abbiano ottenuto qualche risultato su keyword di long tail senza riuscire esattamente a capire per quale motivo ed altri invece credono di aver capito il motivo ma senza avere la possibilità di dimostrarlo perchè hanno carenze dal punto di vista tecnico/informatico.
Proverò a fare un po’ di chiarezza (per quanto possa essere in grado di farlo) sul perchè alcuni credano cose che non possono essere concrete e provate.
Partiamo con alcuni presupposti sulla SEO e sullo scenario dei professionisti italiani:
- La SEO una materia estremamente tecnica
- Molti, troppi SEO sono provenienti da settori decisamente poco tecnici
- Chiunque provi a posizionare keyword prima o poi può ottenere risultati
- Solo chi fa SEO tecnica può spiegare il perchè di un successo o di un fallimento
Premesso questo, vediamo perchè a volte l’inserimento del noto “concetto latente” può far credere di aver trovato la formula magica.
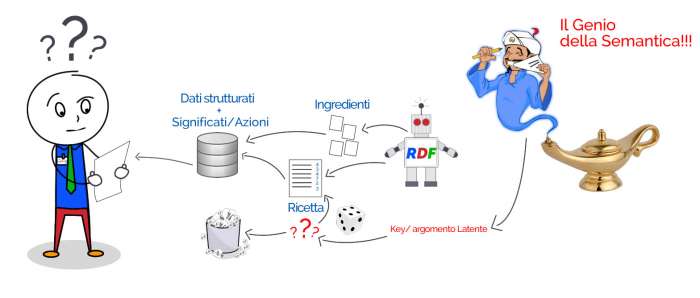
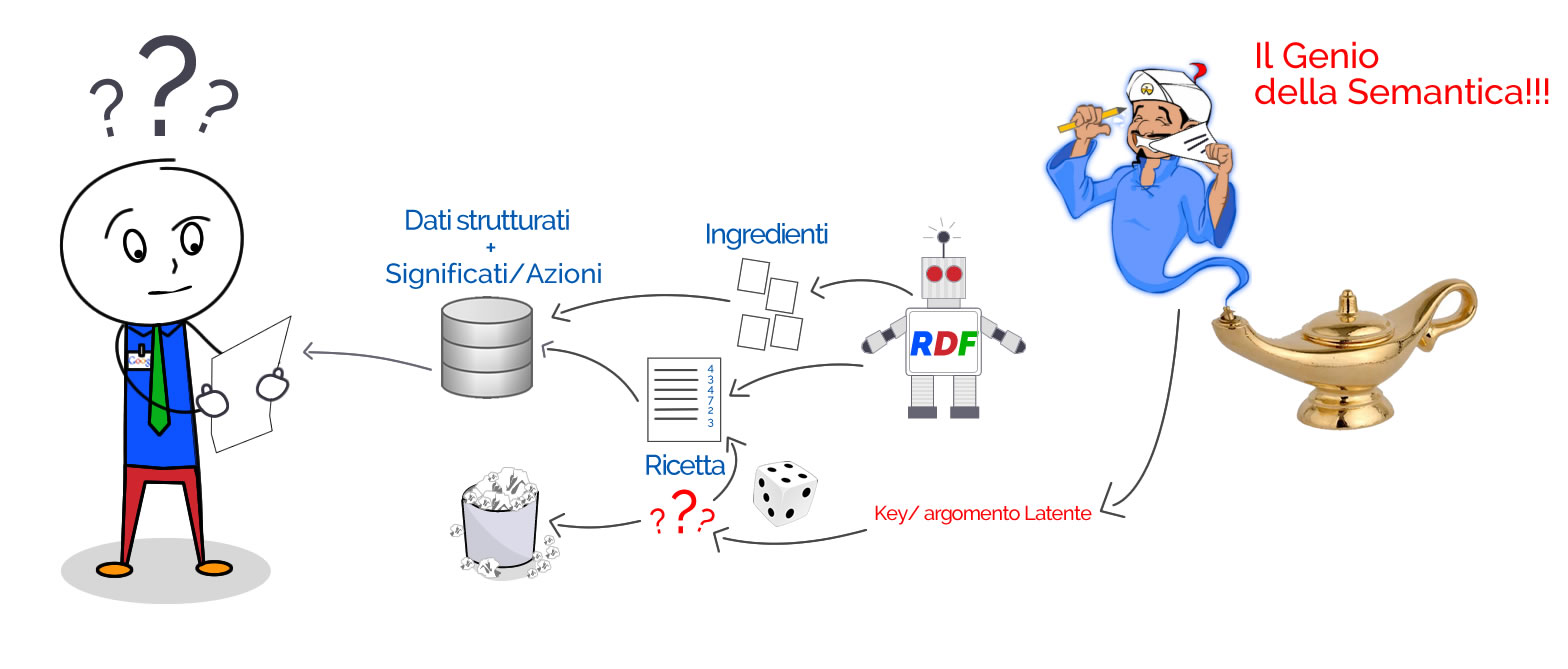
Quello che ho rappresentato come “il genio della semantica” è il copywriter che crede di aver individuato l’argomento latente da inserire nell’articolo per poter posizionare la parola chiave ma, essendo completamente a digiuno riguardo quello che poi accadrà dietro le quinte di Google, potrà trovarsi dinanzi ad due possibili scenari:
- L’argomento che LUI CREDE LATENTE in realtà era già nella “ricetta di Google” e quindi il colpo è fatto
- L’argomento che LUI CREDE LATENTE è realmente troppo latente e finisce nella spazzatura e ti porta Off Topic
Chi non sa come funzioni Google e cade sul punto 1 crederà di aver scoperto qualcosa di fantastico mentre invece non ha fatto altro che migliorare un testo ed aver “toccato i tasti giusti”. Se invece finirà nel punto 2 crederà che ci sia troppa competizione per quella parola chiave e che quindi dipenda dai link/social ed altri fattori Off-Page perchè sarà ancora convinto di aver piazzato il suo colpo geniale.
Come si dovrebbe fare SEO Semantica
Tiriamo le somme di tutto. Google ha introdotto la semantica per non farsi fregare dai testi ottimizzati SEO ma, nonostante tutto, in molti si ostinano ancora a voler manipolare i testi con strane teorie, ma allora come si fa questa SEO Semantica?
La risposta è semplice, semplicissima. Google vuole che ci sia più comunicazione tra i siti web ed il suo crawler, vuole che i siti parlino, per quanto possibile, la stessa lingua dello spider quindi ha messo a disposizione tutte le informazioni di cui avete bisogno per parlare la stessa lingua o almeno provarci.
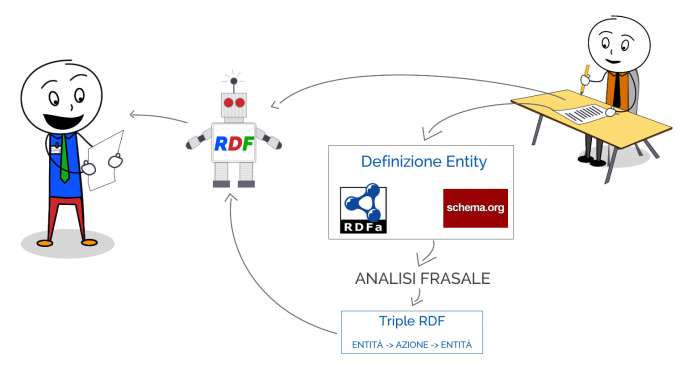
Sappiamo che Google utilizza il Resource Definition Framework per elaborare un testo e tradurlo in qualcosa di più comprensibile per lui, ma sappiamo anche di avere a disposizione strumenti come RDFa (Resource Definition Framework in Attributes) per descrivere univocamente le Entity, delle nostre pagine web, nel formato che piace a Google.
Con l’analisi frasale e con l’aiuto di altri strumenti come ad esempio Schema.org, freebase, Google riesce a capire le relazioni tra le entity e l’intenzione per cui è stata prodotta la pagina web e quali intenzioni di ricerca soddisfi esattamente.
La vera SEO Semantica è qualcosa di molto lontano dalla produzione del contenuto, è come sempre qualcosa di molto tecnico che va implementato nelle pagine inserendo tag specifici e Rich Snippets.
Google è un programma e produce i risultati di ricerca basandosi su calcoli matematici in cui le probabilità sono al centro di tutto. Ottimizzando le proprie pagine web esplicitando le entity, diamo maggiori certezze a Google, proprio quello che vuole per essere contento 🙂
Tanto per capirci, provate a cliccare su queste ricerche su Google, vi mostro cosa intendo e quale sia l’idea della Entity “Ivano Di Biasi” che ho fornito a Google:
Il motivo di tante incomprensioni riguardo l’ambito della semantica è dovuto maggiormente al punto di vista errato di chi prova a capire l’argomento. Molti credono che la semantica sia qualcosa che riguardi noi (chi gestisce un sito web) e la scrittura del testo mentre invece, in realtà, è un problema solo ed unicamente di Google, è lui ad aver bisogno di fare analisi semantiche per capire quello che noi produciamo in maniera naturale e senza alcuna forzatura.
La SEO è e rimarrà sempre una materia tecnica, almeno fino a quando Google rimarrà un programma, per quanto “intelligente” possa diventare. Quando si prova a spiegare qualcosa basandosi su concetti teorici senza fondamento che trovino un riscontro negli algoritmi di Google si sta solo andando fuori strada.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}